

Today is my Birthday. – I met the girl of my dreams when we were just 6 years old. We’ve shared a lifetime of ‘boots on the ground’ experiences together, and that life became the data set for my work in AI.
Our new book is not just a memoir; it is the origin story of a paradigm shift. It’s the journey to the Spherical Thinking and Contextual Reasoning architecture we are building today.
It explains why I believe AI needs to understand the “Whole Person”—because I have spent decades learning what a Whole Person actually is… and test-drove how to introduce this safely to 45,000 end-users over 25 years of research.
We just released the e-book. It is available for instant download.
If you want to understand the human “Ground Truth” behind the technology, start here:
TheOKbook.com
(Thanks Ed Sheeran for such a great song. TURN UP VOLUME.)
ALL Posts
The Engine: Converting Human Context into Computable Vectors
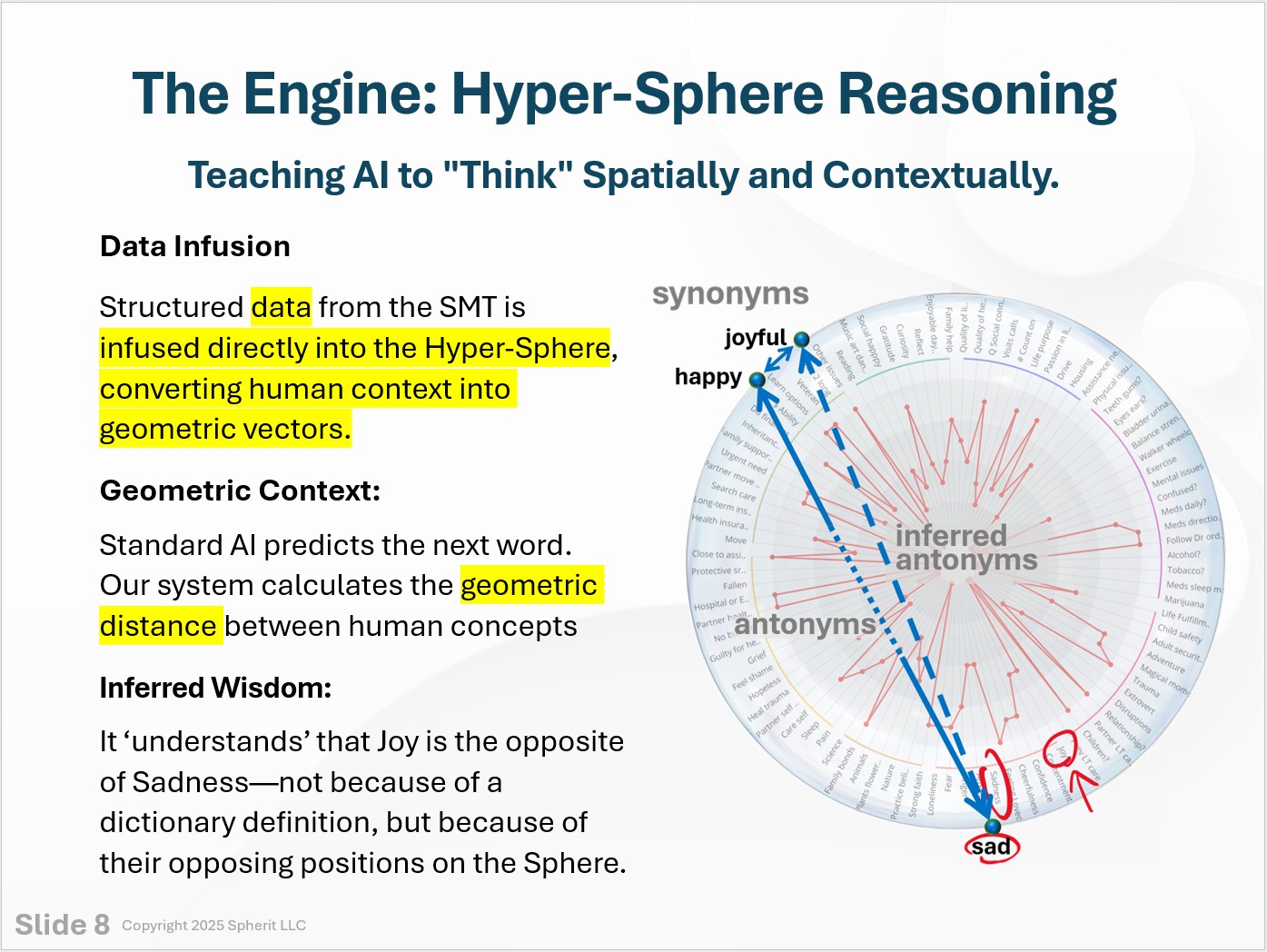
This is the Spherical Modeling Engine (US Patent No. 7,408,544). It solves the “Ontological Gap” by structuring human context not as text, but as geometry.
The diagram illustrates how we map complex human attributes (like trust, tension, or integrity) onto a 3-dimensional coordinate system. By calculating the “Vector Distance” between these points, we generate a mathematical value for “Human Ground Truth” that AI can process, reason with, and align to.
The Ontological Gap: AI is Stuck in a Linear World
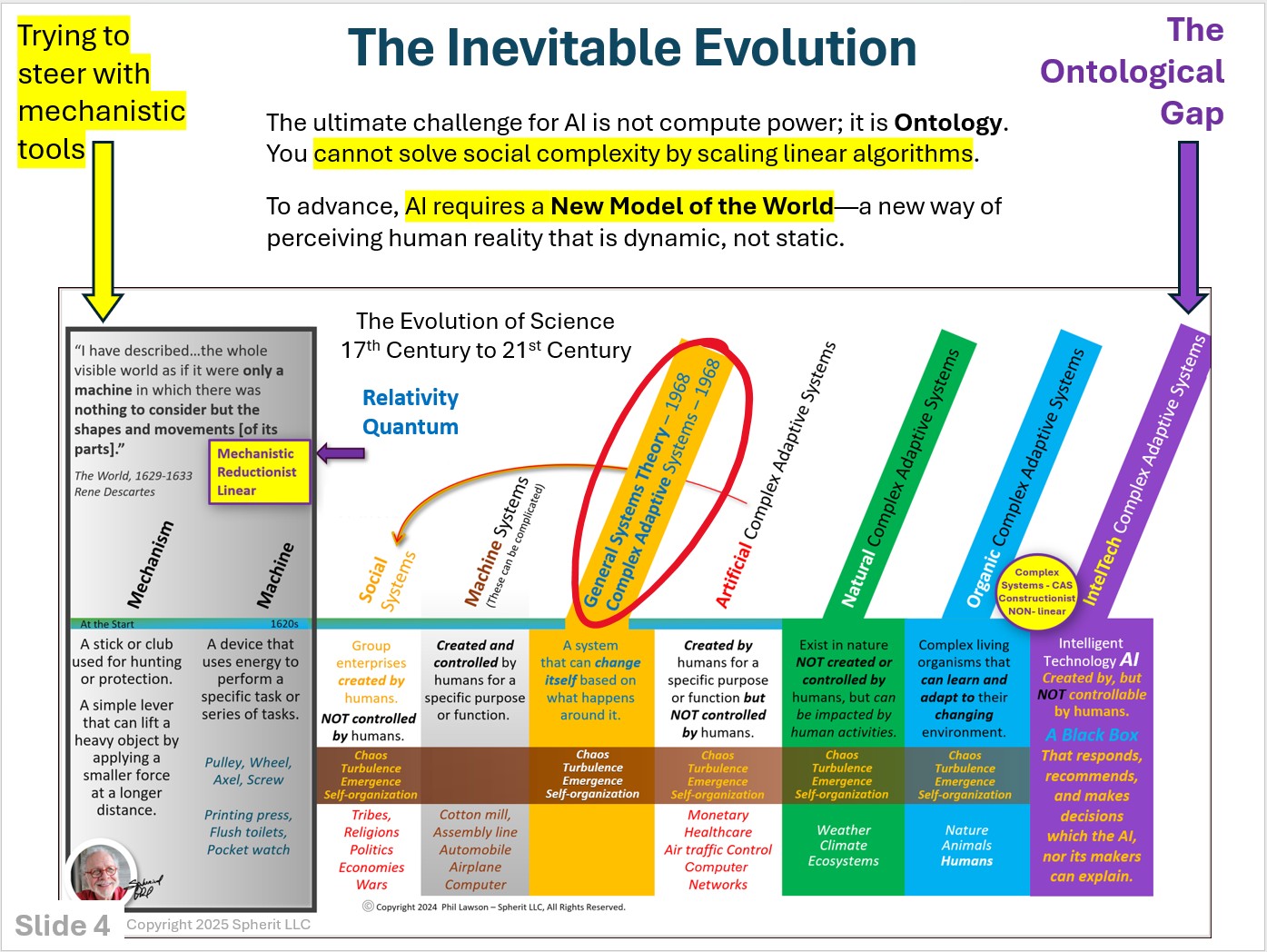
This map illustrates the evolution of scientific paradigms—from the linear, reductionist models of the past to the Complex Adaptive Systems of the 21st century.
While physics and biology moved into “Complexity Science” decades ago, current AI architecture is still largely relying on linear, probabilistic models. This creates an “Ontological Gap.” We are trying to use linear tools to solve non-linear human problems. This diagram shows why simply scaling compute won’t bridge that divide.
HYPER-PERSONALIZED graphs of reasoning and chain of thought PROMPTS for LLMs
Excited to share my journey of creating HYPER-PERSONALIZED graphs of reasoning and chain of thought PROMPTS for LLMs that began 10 years ago before it was a “thing.” Check out this video to learn more about my passion for this innovative approach:
Context Couple Teaser 2024
Contextual Reasoning as an essential human life-skill in our increasingly complex world!
And this is a skill that AI CANNOT DO
but DESPERATELY NEEDS!
Phil and Pam, as the Context Couple, will start a serieis of short vlogs where they will explain and show what contextual reasoning is and more importantlhy, how to develop and practice this essential life skill.
And they will explain and show how, by using contextual reasoning as a base, humans and AI can collaborate.
Please follow us on this exciting journey.
Replacing THINKING with PROMPTING?
Navigating the Cognitive Age—a remarkable leap in human capability and understanding enabled by artificial intelligence. •
🤖I’m concerned that people are completely replacing THINKING with PROMPTING. What’s left is an empty-headed techno zombie commanded by its AI overlord.
The magic of the prompt is the dynamic interplay between humans and tech—in the context of a Socratic dialogue.”
PPL –
Human-AI collaboration will require much more than prompts to the AI.
As we wrote the day we started this blog in May of 2014, “This will require imprinting AI’s genome with social intelligence for human interaction. It will require wisdom-powered coding. It must begin right now.” https://www.socializingai.com/point/
We must move far beyond current AI/LLM prompts, to hyper-personalized situation specific individual prompts.
Restarting blog posts December, 2023
We stopped bloging on this site in 2019 as this topic was ‘early.’ Much has happened in the world of AI since then. It is time to restart.
The Real Reason Tech Struggles With Algorithmic Bias
Yaël Eisenstat is a former CIA officer, national security adviser to vice president Biden, and CSR leader at ExxonMobil. She was elections integrity operations head at Facebook from June to November 2018.
In my six months at Facebook … . I did not know anyone who intentionally wanted to incorporate bias into their work. But I also did not find anyone who actually knew what it meant to counter bias in any true and methodical way. #AI #AIbias @YaelEisenstathttps://t.co/5f1pS3AymP— Phil & Pam Lawson (@SocializingAI) February 14, 2019
Has anyone stopped to ask whether the humans that feed the machines really understand what bias means?
Over more than a decade working as a CIA officer, I went through months of training and routine retraining on structural methods for checking assumptions and understanding cognitive biases.
It is one of the most important skills for an intelligence officer to develop. Analysts and operatives must hone the ability to test assumptions and do the uncomfortable and often time-consuming work of rigorously evaluating one’s own biases when analyzing events. They must also examine the biases of those providing information—assets, foreign governments, media, adversaries—to collectors.
While tech companies often have mandatory “managing bias” training to help with diversity and inclusion issues, I did not see any such training on the field of cognitive bias and decision making, particularly as it relates to how products and processes are built and secured.
I believe that many of my former coworkers at Facebook fundamentally want to make the world a better place. I have no doubt that they feel they are building products that have been tested and analyzed to ensure they are not perpetuating the nastiest biases.
But the company has created its own sort of insular bubble in which its employees’ perception of the world is the product of a number of biases that are engrained within the Silicon Valley tech and innovation scene
Becoming overly reliant on data—which in itself is a product of availability bias—is a huge part of the problem.
In my time at Facebook, I was frustrated by the immediate jump to “data” as the solution to all questions. That impulse often overshadowed necessary critical thinking to ensure that the information provided wasn’t tainted by issues of confirmation, pattern, or other cognitive biases.
To counter algorithmic, machine, and AI bias, human intelligence must be incorporated into solutions, as opposed to an over-reliance on so-called “pure” data.
Attempting to avoid bias without a clear understanding of what that truly means will inevitably fail.
Source: Wired
The AI crossroads: Dystopia vs. utopia
This will further destabilize Europe and the U.S., and I expect that in panic we will see #AI be used in harmful ways in light of other geopolitical crises – danah boyd a Microsoft researcher founder of the Data & Society research institute. @kavehwaddell https://t.co/zbe44xPthb pic.twitter.com/hdQuSE7DOf
— Phil & Pam Lawson (@SocializingAI) December 12, 2018
The necessity of causal models is a paradigm shift
The necessity of causal models is a paradigm shift, creating friction both within statistical practice in several fields of science and with the AI juggernaut. #ai #causalreasoning @yudapearl
Why ‘Why’ Matters: “The Book of Why”https://t.co/a2A74W7xzS
— Phil & Pam Lawson (@SocializingAI) December 11, 2018
Causal diagrams are a form of optimized information compression. Causal diagrams crystalize knowledge, make it more transmissible, more accessible, and reduce evaporation of information.
The necessity for causal models is a paradigm shift that collides with the prevailing AI/ML meme of digital culture. The “causal revolution,” like all real revolutions, will be bumpy and full of friction. I think the resistance to Pearl (see “bashing statistics”, or “this book is a failure”) reflects, and is proportional to, our ‘automagical’ fantasy. And our emotional attachment to cognitive ease. It is my impression that the greater part of the resistance to ‘Why’ may come from those beguiled by the promise of AI/ML relieving us of complexity and the onus of cognitive effort. Those invested with the status quo, who identify with the prevalent ‘data-centric intelligence’ or with conventional statistical practice will also be offended. This is natural behavioral economics: bounded rationality and ‘satisficing’; and is to be expected.
Our becoming better scientists (health scientists, data scientists, computer scientists, social scientists, etc.) will not progress without ‘a push’ (extrinsic information). ‘Why’ is a cause, of progress.
It’s time for research on gender and race in AI to move beyond – ‘fairness.’
We need to ask deeper, more complex questions: Who is in the room when these technologies are created, and which assumptions and worldviews are embedded in this process? How does our identity shape our experiences of AI systems? #AI #AIethics #AIbias https://t.co/MWxJ4k2ErC
— Phil & Pam Lawson (@SocializingAI) December 1, 2018
Decisions will be made on our behalf and increasingly without our awareness,
and those decisions won’t necessarily be in our best interests.
Tomorrow’s big tech companies will leverage intelligence (via AI) and control (via robots) associated with the lives of their users. In such a world, third-party entities may know more about us than we know about ourselves. Decisions will be made on our behalf and increasingly without our awareness, and those decisions won’t necessarily be in our best interests. #AI #AIEthics https://t.co/wvogj1dm5d
— Phil & Pam Lawson (@SocializingAI) November 28, 2018
The Importance of AI Causal Models
we need it to do things like reasoning, learning causality, and exploring the world in order to learn and acquire information…If you have a good causal model of the world you are dealing with, you can generalize even in unfamiliar situations. #ai https://t.co/TmPZeYKfZC
— Phil & Pam Lawson (@SocializingAI) November 17, 2018
You mention causality—in other words, grasping not just patterns in data but why something happens. Why is that important, and why is it so hard?
If you have a good causal model of the world you are dealing with, you can generalize even in unfamiliar situations. That’s crucial. We humans are able to project ourselves into situations that are very different from our day-to-day experience. Machines are not, because they don’t have these causal models.
We can hand-craft them, but that’s not enough. We need machines that can discover causal models. To some extent it’s never going to be perfect. We don’t have a perfect causal model of the reality; that’s why we make a lot of mistakes. But we are much better off at doing this than other animals.
Right now, we don’t really have good algorithms for this, but I think if enough people work at it and consider it important, we will make advances.
The AI Cold War That Could Doom Us All
 … as Beijing began to build up speed, the United States government was slowing to a walk. After President Trump took office, the Obama-era reports on AI were relegated to an archived website.
… as Beijing began to build up speed, the United States government was slowing to a walk. After President Trump took office, the Obama-era reports on AI were relegated to an archived website.
In March 2017, Treasury secretary Steven Mnuchin said that the idea of humans losing jobs because of AI “is not even on our radar screen.” It might be a threat, he added, in “50 to 100 more years.” That same year, China committed itself to building a $150 billion AI industry by 2030.
And what’s at stake is not just the technological dominance of the United States. At a moment of great anxiety about the state of modern liberal democracy, AI in China appears to be an incredibly powerful enabler of authoritarian rule. Is the arc of the digital revolution bending toward tyranny, and is there any way to stop it?
AFTER THE END of the Cold War, conventional wisdom in the West came to be guided by two articles of faith: that liberal democracy was destined to spread across the planet, and that digital technology would be the wind at its back.
As the era of social media kicked in, the techno-optimists’ twin articles of faith looked unassailable. In 2009, during Iran’s Green Revolution, outsiders marveled at how protest organizers on Twitter circumvented the state’s media blackout. A year later, the Arab Spring toppled regimes in Tunisia and Egypt and sparked protests across the Middle East, spreading with all the virality of a social media phenomenon—because, in large part, that’s what it was.
“If you want to liberate a society, all you need is the internet,” said Wael Ghonim, an Egyptian Google executive who set up the primary Facebook group that helped galvanize dissenters in Cairo.
It didn’t take long, however, for the Arab Spring to turn into winter
…. in 2013 the military staged a successful coup. Soon thereafter, Ghonim moved to California, where he tried to set up a social media platform that would favor reason over outrage. But it was too hard to peel users away from Twitter and Facebook, and the project didn’t last long. Egypt’s military government, meanwhile, recently passed a law that allows it to wipe its critics off social media.
Of course, it’s not just in Egypt and the Middle East that things have gone sour. In a remarkably short time, the exuberance surrounding the spread of liberalism and technology has turned into a crisis of faith in both. Overall, the number of liberal democracies in the world has been in steady decline for a decade. According to Freedom House, 71 countries last year saw declines in their political rights and freedoms; only 35 saw improvements.
While the crisis of democracy has many causes, social media platforms have come to seem like a prime culprit.
Which leaves us where we are now: Rather than cheering for the way social platforms spread democracy, we are busy assessing the extent to which they corrode it.
VLADIMIR PUTIN IS a technological pioneer when it comes to cyberwarfare and disinformation. And he has an opinion about what happens next with AI: “The one who becomes the leader in this sphere will be the ruler of the world.”
It’s not hard to see the appeal for much of the world of hitching their future to China. Today, as the West grapples with stagnant wage growth and declining trust in core institutions, more Chinese people live in cities, work in middle-class jobs, drive cars, and take vacations than ever before. China’s plans for a tech-driven, privacy-invading social credit system may sound dystopian to Western ears, but it hasn’t raised much protest there.
In a recent survey by the public relations consultancy Edelman, 84 percent of Chinese respondents said they had trust in their government. In the US, only a third of people felt that way.
… for now, at least, conflicting goals, mutual suspicion, and a growing conviction that AI and other advanced technologies are a winner-take-all game are pushing the two countries’ tech sectors further apart.
A permanent cleavage will come at a steep cost and will only give techno-authoritarianism more room to grow.

Source: Wired (click to read the full article)
Tim Berners-Lee on the huge sociotechnical design challenge
 Coding must mean consciously grappling with ethical choices in addition to architecting systems that respect core human rights like privacy, he suggested.
Coding must mean consciously grappling with ethical choices in addition to architecting systems that respect core human rights like privacy, he suggested.
“Ethics, like technology, is design,”
“As we’re designing the system, we’re designing society. Ethical rules that we choose to put in that design [impact the society]… Nothing is self evident. Everything has to be put out there as something that we think we will be a good idea as a component of our society.”
If your tech philosophy is the equivalent of ‘move fast and break things’ it’s a failure of both imagination and innovation to not also keep rethinking policies and terms of service — “to a certain extent from scratch” — to account for fresh social impacts, he argued in the speech.
He described today’s digital platforms as “sociotechnical systems” — meaning “it’s not just about the technology when you click on the link it is about the motivation someone has to make such a great thing because then they are read and the excitement they get just knowing that other people are reading the things that they have written”.
“We must consciously decide on both of these, both the social side and the technical side,”
“[These platforms are] anthropogenic, made by people … Facebook and Twitter are anthropogenic. They’re made by people. They’ve coded by people. And the people who code them are constantly trying to figure out how to make them better.”
Source: Techcrunch
Making AI Safe May be an Impossible Task
When it comes to creating safe AI and regulating this technology, these great minds have little clue what they’re doing. They don’t even know where to begin.
I met with Michael Page, the Policy and Ethics Advisor at OpenAI.
Beneath the glittering skyscrapers of the self-proclaimed “city of the future,” he told me of the uncertainty that he faces. He spoke of the questions that don’t have answers, and the fantastically high price we’ll pay if we don’t find them.
The conversation began when I asked Page about his role at OpenAI. He responded that his job is to “look at the long-term policy implications of advanced AI.” If you think that this seems a little intangible and poorly defined, you aren’t the only one. I asked Page what that means, practically speaking. He was frank in his answer: “I’m still trying to figure that out.”
Page attempted to paint a better picture of the current state of affairs by noting that, since true artificial intelligence doesn’t actually exist yet, his job is a little more difficult than ordinary.
He noted that, when policy experts consider how to protect the world from AI, they are really trying to predict the future.
They are trying to, as he put it, “find the failure modes … find if there are courses that we could take today that might put us in a position that we can’t get out of.” In short, these policy experts are trying to safeguard the world of tomorrow by anticipating issues and acting today.
The problem is that they may be faced with an impossible task.
Page is fully aware of this uncomfortable possibility, and readily admits it. “I want to figure out what can we do today, if anything. It could be that the future is so uncertain there’s nothing we can do,” he said.
asked for a concrete prediction of where humanity and AI will together be in a year, or in five years, Page didn’t offer false hope: “I have no idea,”
However, Page and OpenAI aren’t alone in working on finding the solutions. He therefore hopes such solutions may be forthcoming: “Hopefully, in a year, I’ll have an answer. Hopefully, in five years, there will be thousands of people thinking about this,” Page said.
Source: Futurism
A Hippocratic Oath for artificial intelligence practitioners

Getty Images
In the forward to Microsoft’s recent book, The Future Computed, executives Brad Smith and Harry Shum proposed that Artificial Intelligence (AI) practitioners highlight their ethical commitments by taking an oath analogous to the Hippocratic Oath sworn by doctors for generations.
In the past, much power and responsibility over life and death was concentrated in the hands of doctors.
Now, this ethical burden is increasingly shared by the builders of AI software.
Future AI advances in medicine, transportation, manufacturing, robotics, simulation, augmented reality, virtual reality, military applications, dictate that AI be developed from a higher moral ground today.
In response, I (Oren Etzioni) edited the modern version of the medical oath to address the key ethical challenges that AI researchers and engineers face …
The oath is as follows:
I swear to fulfill, to the best of my ability and judgment, this covenant:
I will respect the hard-won scientific gains of those scientists and engineers in whose steps I walk, and gladly share such knowledge as is mine with those who are to follow.
I will apply, for the benefit of the humanity, all measures required, avoiding those twin traps of over-optimism and uniformed pessimism.
I will remember that there is an art to AI as well as science, and that human concerns outweigh technological ones.
Most especially must I tread with care in matters of life and death. If it is given me to save a life using AI, all thanks. But it may also be within AI’s power to take a life; this awesome responsibility must be faced with great humbleness and awareness of my own frailty and the limitations of AI. Above all, I must not play at God nor let my technology do so.
I will respect the privacy of humans for their personal data are not disclosed to AI systems so that the world may know.
I will consider the impact of my work on fairness both in perpetuating historical biases, which is caused by the blind extrapolation from past data to future predictions, and in creating new conditions that increase economic or other inequality.
My AI will prevent harm whenever it can, for prevention is preferable to cure.
My AI will seek to collaborate with people for the greater good, rather than usurp the human role and supplant them.
I will remember that I am not encountering dry data, mere zeros and ones, but human beings, whose interactions with my AI software may affect the person’s freedom, family, or economic stability. My responsibility includes these related problems.
I will remember that I remain a member of society, with special obligations to all my fellow human beings.
Source: TechCrunch – Oren Etzioni
Twitter needs and asks for help – study finds that the truth simply cannot compete with hoax and rumor
Twitter wants experts to help it learn to be a less toxic place online.
 Twitter launched a new initiative Thursday to find out exactly what it means to be a healthy social network in 2018.
Twitter launched a new initiative Thursday to find out exactly what it means to be a healthy social network in 2018.

CEO Jack Dorsey tweets acknowledging the problem
The company, which has been plagued by a number of election-meddling, harassment, bot, and scam-related scandals since the 2016 presidential election, announced that it was looking to partner with outside experts to help “identify how we measure the health of Twitter.”
The company said it was looking to find new ways to fight abuse and spam, and to encourage “healthy” debates and conversations.
Twitter is now inviting experts to help define “what health means for Twitter” by submitting proposals for studies.
Source: Wired
Huge MIT Study of ‘Fake News’: Falsehoods Win on Twitter

Krista Kennell / Stone / Catwalker / Shutterstock / The Atlantic
Falsehoods almost always beat out the truth on Twitter, penetrating further, faster, and deeper into the social network than accurate information.
The massive new study analyzes every major contested news story in English across the span of Twitter’s existence—some 126,000 stories, tweeted by 3 million users, over more than 10 years—and finds
that the truth simply cannot compete with hoax and rumor.
By every common metric, falsehood consistently dominates the truth on Twitter, the study finds: Fake news and false rumors reach more people, penetrate deeper into the social network, and spread much faster than accurate stories.
their work has implications for Facebook, YouTube, and every major social network. Any platform that regularly amplifies engaging or provocative content runs the risk of amplifying fake news along with it.
Twitter users seem almost to prefer sharing falsehoods. Even when the researchers controlled for every difference between the accounts originating rumors—like whether that person had more followers or was verified—falsehoods were still 70 percent more likely to get retweeted than accurate news.
In short, social media seems to systematically amplify falsehood at the expense of the truth, and no one—neither experts nor politicians nor tech companies—knows how to reverse that trend.
It is a dangerous moment for any system of government premised on a common public reality.
Source: The Atlantic
The Mueller indictment exposes the danger of Facebook’s focus on Groups

Illustration by Alex Castro / The Verge
A year ago this past Friday, Mark Zuckerberg published a lengthy post titled “Building a Global Community.” It offered a comprehensive statement from the Facebook CEO on how he planned to move the company away from its longtime mission of making the world “more open and connected” to instead create “the social infrastructure … to build a global community.”
“Social media is a short-form medium where resonant messages get amplified many times,” Zuckerberg wrote. “This rewards simplicity and discourages nuance. At its best, this focuses messages and exposes people to different ideas. At its worst, it oversimplifies important topics and pushes us towards extremes.”
By that standard, Robert Mueller’s indictment of of a Russian troll farm last week showed social media at its worst.
Facebook has estimated that 126 million users saw Russian disinformation on the platform during the 2016 campaign. The effects of that disinformation went beyond likes, comments, and shares. Coordinating with unwitting Americans through social media platforms, Russians staged rallies and paid Americans to participate in them. In one case, they hired Americans to build a cage on a flatbed truck and dress up in a Hillary Clinton costume to promote the idea that she should be put in jail.
Russians spent thousands of dollars a month promoting those groups on Facebook and other sites, according to the indictment. They meticulously tracked the growth of their audience, creating and distributing reports on their growing influence. They worked to make their posts seem more authentically American, and to create posts more likely to spread virally through the mechanisms of the social networks.
the dark side of “developing the social infrastructure for community” is now all too visible.
The tools that are so useful for organizing a parenting group are just as effective at coercing large groups of Americans into yelling at each other. Facebook dreams of serving one global community, when in fact it serves — and enables —countless agitated tribes.
The more Facebook pushes us into groups, the more it risks encouraging the kind of polarization that Russia so eagerly exploited.
Source: The Verge
The biggest misconception about artificial intelligence is that we have it
Artificial intelligence still has a long way to go, says IBM’s head of AI, Alexander Gray
“The biggest misconception is that we have it. I wouldn’t even call it AI. I would say it’s right to call the field AI, we’re pursuing AI, but we don’t have it yet,” he said.
Gray says at present, humans are still sorely needed.
“No matter how you look at it, there’s a lot of handcrafting [involved]. We have ever increasingly powerful tools but we haven’t made the leap yet,”
According to Gray, we’re only seeing “human-level performance” for narrowly defined tasks. Most machine learning-based algorithms have to analyze thousands of examples, and haven’t achieved the idea of one-shot or few-shot learnings.
“Once you go slightly beyond that data set and it looks different. Humans win. There will always be things that humans can do that AI can’t do. You still need human data scientists to do the data preparation part — lots of blood and guts stuff that requires open domain knowledge about the world,” he said.
Artificial intelligence is perhaps the most hyped yet misunderstood field of study today.
Gray said while we may not be experiencing the full effects of AI yet, it’s going to happen a lot faster than we think — and that’s where the fear comes in.
“Everything moves on an exponential curve. I really do believe that we will start to see entire classes of jobs getting impacted.
My fear is that we won’t have the social structures and agreements on what we should do to keep pace with that. I’m not sure if that makes me optimistic or pessimistic.”
Source: Yahoo
This is an opportunity for me to correct a wrong – Center for Humane Technology
Early Facebook and Google Employees Form Coalition to Fight What They Built

Jim Steyer, left, and Tristan Harris in Common Sense’s headquarters. Common Sense is helping fund the The Truth About Tech campaign. Peter Prato for The New York Times
A group of Silicon Valley technologists who were early employees at Facebook and Google, alarmed over the ill effects of social networks and smartphones, are banding togethe to challenge the companies they helped build.
The cohort is creating a union of concerned experts called the Center for Humane Technology. Along with the nonprofit media watchdog group Common Sense Media, it also plans an anti-tech addiction lobbying effort and an ad campaign at 55,000 public schools in the United States.
The campaign, titled The Truth About Tech
“We were on the inside,” said Tristan Harris, a former in-house ethicist at Google who is heading the new group. “We know what the companies measure. We know how they talk, and we know how the engineering works.”
An unprecedented alliance of former employees of some of today’s biggest tech companies. Apart from Mr. Harris, the center includes Sandy Parakilas, a former Facebook operations manager; Lynn Fox, a former Apple and Google communications executive; Dave Morin, a former Facebook executive; Justin Rosenstein, who created Facebook’s Like button and is a co-founder of Asana; Roger McNamee, an early investor in Facebook; and Renée DiResta, technologist who studies bots.
“Facebook appeals to your lizard brain — primarily fear and anger. And with smartphones, they’ve got you for every waking moment. This is an opportunity for me to correct a wrong.” Roger McNamee, an early investor in Facebook
Source: NYT
Life at the Intersection of AI and Society
Edits from a Microsoft podcast with Dr. Ece Kamar, a senior researcher in the Adaptive Systems and Interaction Group at Microsoft Research.

Ece Kamar Senior Researcher
I’m very interested in the complementarity between machine intelligence and human intelligence and what kind of value can be generated from using both of them to make daily life better.
We try to build systems that can interact with people, that can work with people and that can be beneficial for people. Our group has a big human component, so we care about modelling the human side. And we also work on machine-learning decision-making algorithms that can make decisions appropriately for the domain they were designed for.
My main area is the intersection between humans and AI.
we are actually at an important point in the history of AI where a lot of critical AI systems are entering the real world and starting to interact with people. So, we are at this inflection point where, whatever AI does, and the way we build AI, have consequences for the society we live in.
So, let’s look for what can augment human intelligence, what can make human intelligence better.” And that’s what my research focuses on. I really look for the complementarity in intelligences, and building these experience that can, in the future, hopefully, create super-human experiences.
So, a lot of the work I do focuses on two big parts: one is how we can build AI systems that can provide value for humans in their daily tasks and making them better. But also thinking about how humans may complement AI systems.
And when we look at our AI practices, it is actually very data-dependent these days … However, data collection is not a real science. We have our insights, we have our assumptions and we do data collection that way. And that data is not always the perfect representation of the world. This creates blind spots. When our data is not the right representation of the world and it’s not representing everything we care about, then our models cannot learn about some of the important things.
“AI is developed by people, with people, for people.”
And when I talk about building AI for people, a lot of the systems we care about are human-driven. We want to be useful for human.
We are thinking about AI algorithms that can bias their decisions based on race, gender, age. They can impact society and there are a lot of areas like judicial decision-making that touches law. And also, for every vertical, we are building these systems and I think we should be working with the domain experts from these verticals. We need to talk to educators. We need to talk to doctors. We need to talk to people who understand what that domain means and all the special considerations we should be careful about.
So, I think if we can understand what this complementary means, and then build AI that can use the power of AI to complement what humans are good at and support them in things that they want to spend time on, I think that is the beautiful future I foresee from the collaboration of humans and machines.
Source: Microsoft Research Podcast
In 2018 AI will gain a moral compass
The ethics of artificial intelligence must be central to its development

Janne Iivonen
Humanity faces a wide range of challenges that are characterised by extreme complexity
… the successful integration of AI technologies into our social and economic world creates its own challenges. They could either help overcome economic inequality or they could worsen it if the benefits are not distributed widely.
They could shine a light on damaging human biases and help society address them, or entrench patterns of discrimination and perpetuate them. Getting things right requires serious research into the social consequences of AI and the creation of partnerships to ensure it works for the public good.
This is why I predict the study of the ethics, safety and societal impact of AI is going to become one of the most pressing areas of enquiry over the coming year.
It won’t be easy: the technology sector often falls into reductionist ways of thinking, replacing complex value judgments with a focus on simple metrics that can be tracked and optimised over time.
There has already been valuable work done in this area. For example, there is an emerging consensus that it is the responsibility of those developing new technologies to help address the effects of inequality, injustice and bias. In 2018, we’re going to see many more groups start to address these issues.
Of course, it’s far simpler to count likes than to understand what it actually means to be liked and the effect this has on confidence or self-esteem.
Progress in this area also requires the creation of new mechanisms for decision-making and voicing that include the public directly. This would be a radical change for a sector that has often preferred to resolve problems unilaterally – or leave others to deal with them.

Mustafa Suleyman co-founder of DeepMind Technologies
We need to do the hard, practical and messy work of finding out what ethical AI really means. If we manage to get AI to work for people and the planet, then the effects could be transformational. Right now, there’s everything to play for.
Source: Wired
DeepMind’s new AI ethics unit
DeepMind made this announcement Oct 2017
Google-owned DeepMind has announced the formation of a major new AI research unit comprised of full-time staff and external advisors

DrAfter123/iStock
As we hand over more of our lives to artificial intelligence systems, keeping a firm grip on their ethical and societal impact is crucial.
DeepMind Ethics & Society (DMES), a unit comprised of both full-time DeepMind employees and external fellows, is the company’s latest attempt to scrutinise the societal impacts of the technologies it creates.
DMES will work alongside technologists within DeepMind and fund external research based on six areas: privacy transparency and fairness; economic impacts; governance and accountability; managing AI risk; AI morality and values; and how AI can address the world’s challenges.
Its aim, according to DeepMind, is twofold: to help technologists understand the ethical implications of their work and help society decide how AI can be beneficial.
“We want these systems in production to be our highest collective selves. We want them to be most respectful of human rights, we want them to be most respectful of all the equality and civil rights laws that have been so valiantly fought for over the last sixty years.” [Mustafa Suleyman]
Source: Wired
How Artificial Intelligence is different from human reasoning

Human decision tree to decide to talk “Bob”
You see a man walking toward you on the street. He reminds you of someone from long ago. Such as a high school classmate, who belonged to the football team? Wasn’t a great player but you were fond of him then. You don’t recall him attending fifth, 10th and 20th reunions. He must have moved away and established his life there and cut off his ties to his friends here.
You look at his face and you really can’t tell if it’s Bob for sure. You had forgotten many of his key features and this man seems to have gained some weight.
The distance between the two of you is quickly closing and your mind is running at full speed trying to decide if it is Bob.
At this moment, you have a few choices. A decision tree will emerge and you will need to choose one of the available options.
In the logic diagram I show, there are some question that is influenced by the emotion. B2) “Nah, let’s forget it” and C) and D) are results of emotional decisions and have little to do with fact this may be Bob or not.
The human decision-making process is often influenced by emotion, which is often independent of fact.
You decision to drop the idea of meeting Bob after so many years is caused by shyness, laziness and/or avoiding some embarrassment in case this man is not Bob. The more you think about this decision-making process, less sure you’d become. After all, if you and Bob hadn’t spoken for 20 years, maybe we should leave the whole thing alone.
Thus, this is clearly the result of human intelligence working.
If this were artificial intelligence, chances are decisions B2, C and D wouldn’t happen. Machines today at their infantile stage of development do not know such emotional feeling as “too much trouble,” hesitation due to fear of failing (Bob says he isn’t Bob), or laziness and or “too complicated.” In some distant time, these complex feelings and deeds driven by the emotion would be realized, I hope. But, not now.
At this point of the state of art of AI, a machine would not hesitate once it makes a decision. That’s because it cannot hesitate. Hesitation is a complex emotional decision that a machine simply cannot perform.
There you see a huge crevice between the human intelligence and AI.
In fact, animals (remember we are also an animal) display complex emotional decisions daily. Now, are you getting some feeling about human intelligence and AI?
Source: Fosters.com
 Shintaro “Sam” Asano was named by the Massachusetts Institute of Technology in 2011 as one of the 10 most influential inventors of the 20th century who improved our lives. He is a businessman and inventor in the field of electronics and mechanical systems who is credited as the inventor of the portable fax machine.
Shintaro “Sam” Asano was named by the Massachusetts Institute of Technology in 2011 as one of the 10 most influential inventors of the 20th century who improved our lives. He is a businessman and inventor in the field of electronics and mechanical systems who is credited as the inventor of the portable fax machine.
Jaron Lanier – the greatest tragedy in the history of computing and …
 A few highlights from THE BUSINESS INSIDER INTERVIEW with Jaron
A few highlights from THE BUSINESS INSIDER INTERVIEW with Jaron
But that general principle — that we’re not treating people well enough with digital systems — still bothers me. I do still think that is very true.
—
Well, this is maybe the greatest tragedy in the history of computing, and it goes like this: there was a well-intentioned, sweet movement in the ‘80s to try to make everything online free. And it started with free software and then it was free music, free news, and other free services.
But, at the same time, it’s not like people were clamoring for the government to do it or some sort of socialist solution. If you say, well, we want to have entrepreneurship and capitalism, but we also want it to be free, those two things are somewhat in conflict, and there’s only one way to bridge that gap, and it’s through the advertising model.
And advertising became the model of online information, which is kind of crazy. But here’s the problem: if you start out with advertising, if you start out by saying what I’m going to do is place an ad for a car or whatever, gradually, not because of any evil plan — just because they’re trying to make their algorithms work as well as possible and maximize their shareholders value and because computers are getting faster and faster and more effective algorithms —
what starts out as advertising morphs into behavior modification.
A second issue is that people who participate in a system of this time, since everything is free since it’s all being monetized, what reward can you get? Ultimately, this system creates assholes, because if being an asshole gets you attention, that’s exactly what you’re going to do. Because there’s a bias for negative emotions to work better in engagement, because the attention economy brings out the asshole in a lot of other people, the people who want to disrupt and destroy get a lot more efficiency for their spend than the people who might be trying to build up and preserve and improve.
—
Q: What do you think about programmers using consciously addicting techniques to keep people hooked to their products?
A: There’s a long and interesting history that goes back to the 19th century, with the science of Behaviorism that arose to study living things as though they were machines.
Behaviorists had this feeling that I think might be a little like this godlike feeling that overcomes some hackers these days, where they feel totally godlike as though they have the keys to everything and can control people
—
I think our responsibility as engineers is to engineer as well as possible, and to engineer as well as possible, you have to treat the thing you’re engineering as a product.
You can’t respect it in a deified way.
It goes in the reverse. We’ve been talking about the behaviorist approach to people, and manipulating people with addictive loops as we currently do with online systems.
In this case, you’re treating people as objects.
It’s the flipside of treating machines as people, as AI does. They go together. Both of them are mistakes
Source: Read the extensive interview at Business Insider
Montreal seeks to be world leader in AI research
 Various computer scientists, researchers, lawyers and other techies have recently been attending bi-monthly meetings in Montreal to discuss life’s big questions — as they relate to our increasingly intelligent machines.
Various computer scientists, researchers, lawyers and other techies have recently been attending bi-monthly meetings in Montreal to discuss life’s big questions — as they relate to our increasingly intelligent machines.
Should a computer give medical advice? Is it acceptable for the legal system to use algorithms in order to decide whether convicts get paroled? Can an artificial agent that spouts racial slurs be held culpable?
And perhaps most pressing for many people: Are Facebook and other social media applications capable of knowing when a user is depressed or suffering a manic episode — and are these people being targeted with online advertisements in order to exploit them at their most vulnerable?
Researchers such as Abhishek Gupta are trying to help Montreal lead the world in ensuring AI is developed responsibly.
“The spotlight of the world is on (Montreal),” said Gupta, an AI ethics researcher at McGill University who is also a software developer in cybersecurity at Ericsson.
His bi-monthly “AI ethics meet-up” brings together people from around the city who want to influence the way researchers are thinking about machine-learning.
“In the past two months we’ve had six new AI labs open in Montreal,” Gupta said. “It makes complete sense we would also be the ones who would help guide the discussion on how to do it ethically.”
In November, Gupta and Universite de Montreal researchers helped create the Montreal Declaration for a Responsible Development of Artificial Intelligence, which is a series of principles seeking to guide the evolution of AI in the city and across the planet.
Its principles are broken down into seven themes: well-being, autonomy, justice, privacy, knowledge, democracy and responsibility.
“How do we ensure that the benefits of AI are available to everyone?” Gupta asked his group. “What types of legal decisions can we delegate to AI?”
Doina Precup, a McGill University computer science professor and the Montreal head of DeepMind … said the global industry is starting to be preoccupied with the societal consequences of machine-learning, and Canadian values encourage the discussion.
“Montreal is a little ahead because we are in Canada,” Precup said. “Canada, compared to other parts of the world, has a different set of values that are more oriented towards ensuring everybody’s wellness. The background and culture of the country and the city matter a lot.”
Source: iPolitics
IEEE launches ethical design guide for AI developers
 As autonomous and intelligent systems become more pervasive, it is essential the designers and developers behind them stop to consider the ethical considerations of what they are unleashing.
As autonomous and intelligent systems become more pervasive, it is essential the designers and developers behind them stop to consider the ethical considerations of what they are unleashing.
That’s the view of the Institute of Electrical and Electronics Engineers (IEEE) which this week released for feedback its second Ethically Aligned Design document in an attempt
to ensure such systems “remain human-centric”.
“These systems have to behave in a way that is beneficial to people beyond reaching functional goals and addressing technical problems. This will allow for an elevated level of trust between people and technology that is needed for its fruitful, pervasive use in our daily lives,” the document states.
“Defining what exactly ‘right’ and ‘good’ are in a digital future is a question of great complexity that places us at the intersection of technology and ethics,”
“Throwing our hands up in air crying ‘it’s too hard’ while we sit back and watch technology careen us forward into a future that happens to us, rather than one we create, is hardly a viable option.
“This publication is a truly game-changing and promising first step in a direction – which has often felt long in coming – toward breaking the protective wall of specialisation that has allowed technologists to disassociate from the societal impacts of their technologies.”
“It will demand that future tech leaders begin to take responsibility for and think deeply about the non-technical impact on disempowered groups, on privacy and justice, on physical and mental health, right down to unpacking hidden biases and moral implications. It represents a positive step toward ensuring the technology we build as humans genuinely benefits us and our planet,” [University of Sydney software engineering Professor Rafael Calvo.]
“We believe explicitly aligning technology with ethical values will help advance innovation with these new tools while diminishing fear in the process” the IEEE said.
Source: Computer World
People want more intelligent technology tools. AI is helping with that.

Jordi Ribas, left, and Kristina Behr, right, showcased Microsoft’s AI advances at an event Wednesday. Photo by Dan DeLong.
These days, people want more intelligent answers: Maybe they’d like to gather the pros and cons of a certain exercise plan or figure out whether the latest Marvel movie is worth seeing. They might even turn to their favorite search tool with only the vaguest of requests, such as, “I’m hungry.”
When people make requests like that, they don’t just want a list of websites. They might want a personalized answer, such as restaurant recommendations based on the city they are traveling in. Or they might want a variety of answers, so they can get different perspectives on a topic. They might even need help figuring out the right question to ask.
At a Microsoft event in San Francisco on Wednesday, Microsoft executives showcased a number of advances in its Bing search engine, Cortana intelligent assistant and Microsoft Office 365 productivity tools that use artificial intelligence to help people get more nuanced information and assist with more complex needs.
“AI has come a long way in the ability to find information, but making sense of that information is the real challenge,” said Kristina Behr, a partner design and planning program manager with Microsoft’s Artificial Intelligence and Research group.
Microsoft demonstrated some of the most recent AI-driven advances in intelligent search that are aimed at giving people richer, more useful information.
Another new, AI-driven advance in Bing is aimed at getting people multiple viewpoints on a search query that might be more subjective.
For example, if you ask Bing “is cholesterol bad,” you’ll see two different perspectives on that question.
That’s part of Microsoft’s effort to acknowledge that sometimes a question doesn’t have a clear black and white answer.
“As Bing, what we want to do is we want to provide the best results from the overall web. We want to be able to find the answers and the results that are the most comprehensive, the most relevant and the most trustworthy,” Ribas said.
“Often people are seeking answers that go beyond something that is a mathematical equation. We want to be able to frame those opinions and articulate them in a way that’s also balanced and objective.”
Source: Microsoft
Trouble with #AI Bias – Kate Crawford
 This article attempts to bring our readers to Kate’s brilliant Keynote speech at NIPS 2017. It talks about different forms of bias in Machine Learning systems and the ways to tackle such problems.
This article attempts to bring our readers to Kate’s brilliant Keynote speech at NIPS 2017. It talks about different forms of bias in Machine Learning systems and the ways to tackle such problems.
The rise of Machine Learning is every bit as far reaching as the rise of computing itself.
A vast new ecosystem of techniques and infrastructure are emerging in the field of machine learning and we are just beginning to learn their full capabilities. But with the exciting things that people can do, there are some really concerning problems arising.
Forms of bias, stereotyping and unfair determination are being found in machine vision systems, object recognition models, and in natural language processing and word embeddings. High profile news stories about bias have been on the rise, from women being less likely to be shown high paying jobs to gender bias and object recognition datasets like MS COCO, to racial disparities in education AI systems.
What is bias?
Bias is a skew that produces a type of harm.
Where does bias come from?
Commonly from Training data. It can be incomplete, biased or otherwise skewed. It can draw from non-representative samples that are wholly defined before use. Sometimes it is not obvious because it was constructed in a non-transparent way. In addition to human labeling, other ways that human biases and cultural assumptions can creep in ending up in exclusion or overrepresentation of subpopulation. Case in point: stop-and-frisk program data used as training data by an ML system. This dataset was biased due to systemic racial discrimination in policing.
Harms of allocation
Majority of the literature understand bias as harms of allocation. Allocative harm is when a system allocates or withholds certain groups, an opportunity or resource. It is an economically oriented view primarily. Eg: who gets a mortgage, loan etc.
Allocation is immediate, it is a time-bound moment of decision making. It is readily quantifiable. In other words, it raises questions of fairness and justice in discrete and specific transactions.
Harms of representation
It gets tricky when it comes to systems that represent society but don’t allocate resources. These are representational harms. When systems reinforce the subordination of certain groups along the lines of identity like race, class, gender etc.
It is a long-term process that affects attitudes and beliefs. It is harder to formalize and track. It is a diffused depiction of humans and society. It is at the root of all of the other forms of allocative harm.
What can we do to tackle these problems?
- Start working on fairness forensics
- Test our systems: eg: build pre-release trials to see how a system is working across different populations
- How do we track the life cycle of a training dataset to know who built it and what the demographics skews might be in that dataset
- Start taking interdisciplinarity seriously
- Working with people who are not in our field but have deep expertise in other areas Eg: FATE (Fairness Accountability Transparency Ethics) group at Microsoft Research
- Build spaces for collaboration like the AI now institute.
- Think harder on the ethics of classification
The ultimate question for fairness in machine learning is this.
Who is going to benefit from the system we are building? And who might be harmed?
Source: Datahub
Kate Crawford is a Principal Researcher at Microsoft Research and a Distinguished Research Professor at New York University. She has spent the last decade studying the social implications of data systems, machine learning, and artificial intelligence. Her recent publications address data bias and fairness, and social impacts of artificial intelligence among others.
Former Facebook exec says social media is ripping apart society

Chamath Palihapitiya speaks at a Vanity Fair event in October 2016. Photo by Mike Windle/Getty Images for Vanity Fair
![]() Chamath Palihapitiya, who joined Facebook in 2007 and became its vice president for user growth, said he feels “tremendous guilt” about the company he helped make.
Chamath Palihapitiya, who joined Facebook in 2007 and became its vice president for user growth, said he feels “tremendous guilt” about the company he helped make.
“I think we have created tools that are ripping apart the social fabric of how society works”
Palihapitiya’s criticisms were aimed not only at Facebook, but the wider online ecosystem.
“The short-term, dopamine-driven feedback loops we’ve created are destroying how society works,” he said, referring to online interactions driven by “hearts, likes, thumbs-up.” “No civil discourse, no cooperation; misinformation, mistruth. And it’s not an American problem — this is not about Russians ads. This is a global problem.”
He went on to describe an incident in India where hoax messages about kidnappings shared on WhatsApp led to the lynching of seven innocent people.
“That’s what we’re dealing with,” said Palihapitiya. “And imagine taking that to the extreme, where bad actors can now manipulate large swathes of people to do anything you want. It’s just a really, really bad state of affairs.”
In his talk, Palihapitiya criticized not only Facebook, but Silicon Valley’s entire system of venture capital funding.
He said that investors pump money into “shitty, useless, idiotic companies,” rather than addressing real problems like climate change and disease.
Source: The Verge
UPDATE: FACEBOOK RESPONDS
Chamath has not been at Facebook for over six years. When Chamath was at Facebook we were focused on building new social media experiences and growing Facebook around the world. Facebook was a very different company back then and as we have grown we have realised how our responsibilities have grown too. We take our role very seriously and we are working hard to improve. We’ve done a lot of work and research with outside experts and academics to understand the effects of our service on well-being, and we’re using it to inform our product development. We are also making significant investments more in people, technology and processes, and – as Mark Zuckerberg said on the last earnings call – we are willing to reduce our profitability to make sure the right investments are made.
Source: CNBC
Are there some things we just shouldn’t build? #AI
 The prestigious Neural Information Processing Systems conference have a new topic on their agenda. Alongside the usual … concern about AI’s power.
The prestigious Neural Information Processing Systems conference have a new topic on their agenda. Alongside the usual … concern about AI’s power.
Kate Crawford … urged attendees to start considering, and finding ways to mitigate, accidental or intentional harms caused by their creations. “
“Amongst the very real excitement about what we can do there are also some really concerning problems arising”
“In domains like medicine we can’t have these models just be a black box where something goes in and you get something out but don’t know why,” says Maithra Raghu, a machine-learning researcher at Google. On Monday, she presented open-source software developed with colleagues that can reveal what a machine-learning program is paying attention to in data. It may ultimately allow a doctor to see what part of a scan or patient history led an AI assistant to make a particular diagnosis.
“If you have a diversity of perspectives and background you might be more likely to check for bias against different groups” Hanna Wallach a researcher at Microsoft
Others in Long Beach hope to make the people building AI better reflect humanity. Like computer science as a whole, machine learning skews towards the white, male, and western. A parallel technical conference called Women in Machine Learning has run alongside NIPS for a decade. This Friday sees the first Black in AI workshop, intended to create a dedicated space for people of color in the field to present their work.
Towards the end of her talk Tuesday, Crawford suggested civil disobedience could shape the uses of AI. She talked of French engineer Rene Carmille, who sabotaged tabulating machines used by the Nazis to track French Jews. And she told today’s AI engineers to consider the lines they don’t want their technology to cross. “Are there some things we just shouldn’t build?” she asked.
Source: Wired
Artificial intelligence doesn’t have to be evil. We just have to teach it to be good
 Training an AI platform on social media data, with the intent to reproduce a “human” experience, is fraught with risk. You could liken it to raising a baby on a steady diet of Fox News or CNN, with no input from its parents or social institutions. In either case, you might be breeding a monster.
Training an AI platform on social media data, with the intent to reproduce a “human” experience, is fraught with risk. You could liken it to raising a baby on a steady diet of Fox News or CNN, with no input from its parents or social institutions. In either case, you might be breeding a monster.
Ultimately, social data — alone — represents neither who we actually are nor who we should be. Deeper still, as useful as the social graph can be in providing a training set for AI, what’s missing is a sense of ethics or a moral framework to evaluate all this data. From the spectrum of human experience shared on Twitter, Facebook and other networks, which behaviors should be modeled and which should be avoided? Which actions are right and which are wrong? What’s good … and what’s evil?
Here’s where science comes up short. The answers can’t be gleaned from any social data set. The best analytical tools won’t surface them, no matter how large the sample size.
But they just might be found in the Bible. And the Koran, the Torah, the Bhagavad Gita and the Buddhist Sutras. They’re in the work of Aristotle, Plato, Confucius, Descartes and other philosophers both ancient and modern.
AI, to be effective, needs an ethical underpinning. Data alone isn’t enough. AI needs religion — a code that doesn’t change based on context or training set.
In place of parents and priests, responsibility for this ethical education will increasingly rest on frontline developers and scientists.
As emphasized by leading AI researcher Will Bridewell, it’s critical that future developers are “aware of the ethical status of their work and understand the social implications of what they develop.” He goes so far as to advocate study in Aristotle’s ethics and Buddhist ethics so they can “better track intuitions about moral and ethical behavior.”
On a deeper level, responsibility rests with the organizations that employ these developers, the industries they’re part of, the governments that regulate those industries and — in the end — us.
Source: Recode Ryan Holmes is the founder and CEO of Hootsuite.
How a half-educated tech elite delivered us into chaos

Donald Trump meeting PayPal co-founder Peter Thiel and Apple CEO Tim Cook in December last year. Photograph: Evan Vucci/AP
One of the biggest puzzles about our current predicament with fake news and the weaponisation of social media is why the folks who built this technology are so taken aback by what has happened.
We have a burgeoning genre of “OMG, what have we done?” angst coming from former Facebook and Google employees who have begun to realise that the cool stuff they worked on might have had, well, antisocial consequences.
Put simply, what Google and Facebook have built is a pair of amazingly sophisticated, computer-driven engines for extracting users’ personal information and data trails, refining them for sale to advertisers in high-speed data-trading auctions that are entirely unregulated and opaque to everyone except the companies themselves.
The purpose of this infrastructure was to enable companies to target people with carefully customised commercial messages and, as far as we know, they are pretty good at that.
It never seems to have occurred to them that their advertising engines could also be used to deliver precisely targeted ideological and political messages to voters. Hence the obvious question: how could such smart people be so stupid?
My hunch is it has something to do with their educational backgrounds. Take the Google co-founders. Sergey Brin studied mathematics and computer science. His partner, Larry Page, studied engineering and computer science. Zuckerberg dropped out of Harvard, where he was studying psychology and computer science, but seems to have been more interested in the latter.
Now mathematics, engineering and computer science are wonderful disciplines – intellectually demanding and fulfilling. And they are economically vital for any advanced society. But mastering them teaches students very little about society or history – or indeed about human nature.
As a consequence, the new masters of our universe are people who are essentially only half-educated. They have had no exposure to the humanities or the social sciences, the academic disciplines that aim to provide some understanding of how society works, of history and of the roles that beliefs, philosophies, laws, norms, religion and customs play in the evolution of human culture.
We are now beginning to see the consequences of the dominance of this half-educated elite.
Source: The Gaurdian – John Naughton is professor of the public understanding of technology at the Open University.
Artificial Intelligence researchers are “basically writing policy in code”
 A discussion between OpenAI Director Shivon Zilis and AI Fund Director of Ethics and Governance Tim Hwang, and both shared perspective on AI’s progress, its public perception, and how we can help ensure its responsible development going forward.
A discussion between OpenAI Director Shivon Zilis and AI Fund Director of Ethics and Governance Tim Hwang, and both shared perspective on AI’s progress, its public perception, and how we can help ensure its responsible development going forward.
Hwang brought up the fact that artificial intelligence researchers are, in some ways, “basically writing policy in code” because of how influential the particular perspectives or biases inherent in these systems will be, and suggested that researchers could actually consciously set new cultural norms via their work.
Zilis added that the total number of people setting the tone for incredibly intelligent AI is probably “in the low thousands.”
She added that this means we likely need more crossover discussion between this community and those making policy decisions, and Hwang added that currently, there’s
“no good way for the public at large to signal” what moral choices should be made around the direction of AI development.
Zilis concluded that she has three guiding principles in terms of how she thinks about the future of responsible artificial intelligence development:
- First, the tech’s coming no matter what, so we need to figure out how to bend its arc with intent.
- Second, how do we get more people involved in the conversation?
- And finally, we need to do our best to front load the regulation and public discussion needed on the issue, since ultimately, it’s going to be a very powerful technology.
Source: TechCrunch
AI more than just another industrial revolution
This is more than just another industrial revolution. This is something new that transcends humankind and even biology. It is a privilege to witness its beginnings, and contribute something to it.

{kind=link}
Source: Scientific American Blog Network
The idea that you had no idea any of this was happening strains my credibility

From left: Twitter’s acting general counsel Sean Edgett, Facebook’s general counsel Colin Stretch and Google’s senior vice president and general counsel Kent Walker, testify before the House Intelligence Committee on Wednesday, Nov. 1, 2017. Manuel Balce Ceneta/AP
Members of Congress confessed how difficult it was for them to even wrap their minds around how today’s Internet works — and can be abused. And for others, the hearings finally drove home the magnitude of the Big Tech platforms.
Sen. John Kennedy, R-La., marveled on Tuesday when Facebook said it could track the source of funding for all 5 million of its monthly advertisers.
“I think you do enormous good, but your power scares me,” he said.
There appears to be no quick patch for the malware afflicting America’s political life.
Over the course of three congressional hearings Tuesday and Wednesday, lawmakers fulminated, Big Tech witnesses were chastened but no decisive action appears to be in store to stop a foreign power from harnessing digital platforms to try to shape the information environment inside the United States.
Legislation offered in the Senate — assuming it passed, months or more from now — would change the calculus slightly: requiring more disclosure and transparency for political ads on Facebook and Twitter and other social platforms.
Even if it became law, however, it would not stop such ads from being sold, nor heal the deep political divisions exploited last year by foreign influence-mongers. The legislation also couldn’t stop a foreign power from using all the other weapons in its arsenal against the U.S., including cyberattacks, the deployment of human spies and others.
“Candidly, your companies know more about Americans, in many ways, than the United States government does. The idea that you had no idea any of this was happening strains my credibility,” Senate Intelligence Committee Vice Chairman Mark Warner, D.-Va.
The companies also made clear they condemn the uses of their services they’ve discovered, which they said violate their policies in many cases.
They also talked more about the scale of the Russian digital operation they’ve uncovered up to this point — which is eye-watering: Facebook general counsel Colin Stretch acknowledged that as many as 150 million Americans may have seen posts or other content linked to Russia’s influence campaign in the 2016 cycle
“There is one thing I’m certain of, and it’s this: Given the complexity of what we have seen, if anyone tells you they have figured it out, they are kidding ourselves. And we can’t afford to kid ourselves about what happened last year — and continues to happen today.” Senate Intelligence Committee Chairman Richard Burr, R-N.C.
Source: NPR
Does Even Mark Zuckerberg Know What Facebook Is?
 In a statement broadcast live on Facebook on September 21 and subsequently posted to his profile page, Zuckerberg pledged to increase the resources of Facebook’s security and election-integrity teams and to work “proactively to strengthen the democratic process.”
In a statement broadcast live on Facebook on September 21 and subsequently posted to his profile page, Zuckerberg pledged to increase the resources of Facebook’s security and election-integrity teams and to work “proactively to strengthen the democratic process.”
It was an admirable commitment. But reading through it, I kept getting stuck on one line: “We have been working to ensure the integrity of the German elections this weekend,” Zuckerberg writes. It’s a comforting sentence, a statement that shows Zuckerberg and Facebook are eager to restore trust in their system.
But … it’s not the kind of language we expect from media organizations, even the largest ones. It’s the language of governments, or political parties, or NGOs. A private company, working unilaterally to ensure election integrity in a country it’s not even based in?
Facebook has grown so big, and become so totalizing, that we can’t really grasp it all at once.
Like a four-dimensional object, we catch slices of it when it passes through the three-dimensional world we recognize. In one context, it looks and acts like a television broadcaster, but in this other context, an NGO. In a recent essay for the London Review of Books, John Lanchester argued that for all its rhetoric about connecting the world, the company is ultimately built to extract data from users to sell to advertisers. This may be true, but Facebook’s business model tells us only so much about how the network shapes the world.
Between March 23, 2015, when Ted Cruz announced his candidacy, and November 2016, 128 million people in America created nearly 10 billion Facebook posts, shares, likes, and comments about the election. (For scale, 137 million people voted last year.)
In February 2016, the media theorist Clay Shirky wrote about Facebook’s effect: “Reaching and persuading even a fraction of the electorate used to be so daunting that only two national orgs” — the two major national political parties — “could do it. Now dozens can.”
It used to be if you wanted to reach hundreds of millions of voters on the right, you needed to go through the GOP Establishment. But in 2016, the number of registered Republicans was a fraction of the number of daily American Facebook users, and the cost of reaching them directly was negligible.
Tim Wu, the Columbia Law School professor
“Facebook has the same kind of attentional power [as TV networks in the 1950s], but there is not a sense of responsibility,” he said. “No constraints. No regulation. No oversight. Nothing. A bunch of algorithms, basically, designed to give people what they want to hear.”
It tends to get forgotten, but Facebook briefly ran itself in part as a democracy: Between 2009 and 2012, users were given the opportunity to vote on changes to the site’s policy. But voter participation was minuscule, and Facebook felt the scheme “incentivized the quantity of comments over their quality.” In December 2012, that mechanism was abandoned “in favor of a system that leads to more meaningful feedback and engagement.”
Facebook had grown too big, and its users too complacent, for democracy.
Source: NY Magazine
Put Humans at the Center of AI

As the director of Stanford’s AI Lab and now as a chief scientist of Google Cloud, Fei-Fei Li is helping to spur the AI revolution. But it’s a revolution that needs to include more people. She spoke with MIT Technology Review senior editor Will Knight about why everyone benefits if we emphasize the human side of the technology.
Why did you join Google?
Researching cutting-edge AI is very satisfying and rewarding, but we’re seeing this great awakening, a great moment in history. For me it’s very important to think about AI’s impact in the world, and one of the most important missions is to democratize this technology. The cloud is this gigantic computing vehicle that delivers computing services to every single industry.
What have you learned so far?
We need to be much more human-centered.
If you look at where we are in AI, I would say it’s the great triumph of pattern recognition. It is very task-focused, it lacks contextual awareness, and it lacks the kind of flexible learning that humans have.
We also want to make technology that makes humans’ lives better, our world safer, our lives more productive and better. All this requires a layer of human-level communication and collaboration.
When you are making a technology this pervasive and this important for humanity, you want it to carry the values of the entire humanity, and serve the needs of the entire humanity.
If the developers of this technology do not represent all walks of life, it is very likely that this will be a biased technology. I say this as a technologist, a researcher, and a mother. And we need to be speaking about this clearly and loudly.
Source: MIT Technology Review
Why we launched DeepMind Ethics & Society
We believe AI can be of extraordinary benefit to the world, but only if held to the highest ethical standards.
 Technology is not value neutral, and technologists must take responsibility for the ethical and social impact of their work.
Technology is not value neutral, and technologists must take responsibility for the ethical and social impact of their work.
As history attests, technological innovation in itself is no guarantee of broader social progress. The development of AI creates important and complex questions. Its impact on society—and on all our lives—is not something that should be left to chance. Beneficial outcomes and protections against harms must be actively fought for and built-in from the beginning. But in a field as complex as AI, this is easier said than done.
As scientists developing AI technologies, we have a responsibility to conduct and support open research and investigation into the wider implications of our work. At DeepMind, we start from the premise that all AI applications should remain under meaningful human control, and be used for socially beneficial purposes.
So today we’re launching a new research unit, DeepMind Ethics & Society, to complement our work in AI science and application. This new unit will help us explore and understand the real-world impacts of AI. It has a dual aim: to help technologists put ethics into practice, and to help society anticipate and direct the impact of AI so that it works for the benefit of all.
If AI technologies are to serve society, they must be shaped by society’s priorities and concerns.
Source: DeepMind
Facebook and Google promote Las Vegas-shooting hoaxes
 The missteps underscore how misinformation continues to undermine the credibility of Silicon Valley’s biggest companies.
The missteps underscore how misinformation continues to undermine the credibility of Silicon Valley’s biggest companies.
Accuracy matters in the moments after a tragedy. Facts can help catch the suspects, save lives and prevent a panic.
But in the aftermath of the deadly mass shooting in Las Vegas on Sunday, the world’s two biggest gateways for information, Google and Facebook, did nothing to quell criticism that they amplify fake news when they steer readers toward hoaxes and misinformation gathering momentum on fringe sites.
Google posted under its “top stories” conspiracy-laden links from 4chan — home to some of the internet’s most ardent trolls. It also promoted a now-deleted story from Gateway Pundit and served videos on YouTube of dubious origin.
The posts all had something in common: They identified the wrong assailant.
Facebook’s Crisis Response page, a hub for users to stay informed and mobilize during disasters, perpetuated the same rumors by linking to sites such as Alt-Right News and End Time Headlines, according to Fast Company.
The platforms have immense influence on what gets seen and read. More than two-thirds of Americans report getting at least some of their news from social media, according to the Pew Research Center. A separate global study published by Edelman last year found that more people trusted search engines (63%) for news and information than traditional media such as newspapers and television (58%).
Still, skepticism abounds that the companies beholden to shareholders are equipped to protect the public from misinformation and recognize the threat their platforms pose to democratic societies.
Source: LA Times
Sundar Pichai says the future of Google is AI. But can he fix the algorithm?
 I was asking in the context of the aftermath of the 2016 election and the misinformation that companies like Facebook, Twitter, and Google were found to have spread.
I was asking in the context of the aftermath of the 2016 election and the misinformation that companies like Facebook, Twitter, and Google were found to have spread.
“I view it as a big responsibility to get it right,” he says. “I think we’ll be able to do these things better over time. But I think the answer to your question, the short answer and the only answer, is we feel huge responsibility.”
But it’s worth questioning whether Google’s systems are making the rightdecisions, even as they make some decisions much easier.
People are already skittish about how much Google knows about them, and they are unclear on how to manage their privacy settings. Pichai thinks that’s another one of those problems that AI could fix, “heuristically.”
“Down the line, the system can be much more sophisticated about understanding what is sensitive for users, because it understands context better,” Pichai says. “[It should be] treating health-related information very differently from looking for restaurants to eat with friends.” Instead of asking users to sift through a “giant list of checkboxes,” a user interface driven by AI could make it easier to manage.
Of course, what’s good for users versus what’s good for Google versus what’s good for the other business that rely on Google’s data is a tricky question. And it’s one that AI alone can’t solve. Google is responsible for those choices, whether they’re made by people or robots.
The amount of scrutiny companies like Facebook and Google — and Google’s YouTube division — face over presenting inaccurate or outright manipulative information is growing every day, and for good reason.
Pichai thinks that Google’s basic approach for search can also be used for surfacing good, trustworthy content in the feed. “We can still use the same core principles we use in ranking around authoritativeness, trust, reputation.
What he’s less sure about, however, is what to do beyond the realm of factual information — with genuine opinion: “I think the issue we all grapple with is how do you deal with the areas where people don’t agree or the subject areas get tougher?”
When it comes to presenting opinions on its feed, Pichai wonders if Google could “bring a better perspective, rather than just ranking alone. … Those are early areas of exploration for us, but I think we could do better there.”
Source: The Verge
The idea that Silicon Valley is the darling of our markets and of our society … is definitely turning
“Personally, I think the idea that fake news on Facebook, it’s a very small amount of the content, influenced the election in any way is a pretty crazy idea.”

Facebook CEO Mark Zuckerberg’s company recently said it would turn over to Congress more than 3,000 politically themed advertisements that were bought by suspected Russian operatives. (Eric Risberg/AP
Nine days after Facebook chief executive Mark Zuckerberg dismissed as “crazy” the idea that fake news on his company’s social network played a key role in the U.S. election, President Barack Obama pulled the youthful tech billionaire aside and delivered what he hoped would be a wake-up call.
Obama made a personal appeal to Zuckerberg to take the threat of fake news and political disinformation seriously. Unless Facebook and the government did more to address the threat, Obama warned, it would only get worse in the next presidential race.
“There’s been a systematic failure of responsibility. It’s rooted in their overconfidence that they know best, their naivete about how the world works, their extensive effort to avoid oversight, and their business model of having very few employees so that no one is minding the store.” Zeynep Tufekci
Zuckerberg acknowledged the problem posed by fake news. But he told Obama that those messages weren’t widespread on Facebook and that there was no easy remedy, according to people briefed on the exchange
One outcome of those efforts was Zuckerberg’s admission on Thursday that Facebook had indeed been manipulated and that the company would now turn over to Congress more than 3,000 politically themed advertisements that were bought by suspected Russian operatives.
These issues have forced Facebook and other Silicon Valley companies to weigh core values, including freedom of speech, against the problems created when malevolent actors use those same freedoms to pump messages of violence, hate and disinformation.
Congressional investigators say the disclosure only scratches the surface. One called Facebook’s discoveries thus far “the tip of the iceberg.” Nobody really knows how many accounts are out there and how to prevent more of them from being created to shape the next election — and turn American society against itself.
“There is no question that the idea that Silicon Valley is the darling of our markets and of our society — that sentiment is definitely turning,” said Tim O’Reilly, an adviser to tech executives and chief executive of the influential Silicon Valley-based publisher O’Reilly Media
Source: Washington Post
The idea was to help you and I make better decisions amid cognitive overload

IBM Chairman, President, and Chief Executive Officer Ginni Rometty. PHOTOGRAPHER: STEPHANIE SINCLAIR FOR BLOOMBERG BUSINESSWEEK
If I considered the initials AI, I would have preferred augmented intelligence.
It’s the idea that each of us are going to need help on all important decisions.
A study said on average that a third of your decisions are really great decisions, a third are not optimal, and a third are just wrong. We’ve estimated the market is $2 billion for tools to make better decisions.
That’s what led us all to really calling it cognitive
“Look, we really think this is about man and machine, not man vs. machine. This is an era—really, an era that will play out for decades in front of us.”
We set out to build an AI platform for business.
AI would be vertical. You would train it to know medicine. You would train it to know underwriting of insurance. You would train it to know financial crimes. Train it to know oncology. Train it to know weather. And it isn’t just about billions of data points. In the regulatory world, there aren’t billions of data points. You need to train and interpret something with small amounts of data.
This is really another key point about professional AI. Doctors don’t want black-and-white answers, nor does any profession. If you’re a professional, my guess is when you interact with AI, you don’t want it to say, “Here is an answer.”
What a doctor wants is, “OK, give me the possible answers. Tell my why you believe it. Can I see the research, the evidence, the ‘percent confident’? What more would you like to know?”
It’s our responsibility if we build this stuff to guide it safely into the world.
Source: Bloomberg
Siri as a therapist, Apple is seeking engineers who understand psychology
 PL – Looks like Siri needs more help to understand.
PL – Looks like Siri needs more help to understand.
“People have serious conversations with Siri. People talk to Siri about all kinds of things, including when they’re having a stressful day or have something serious on their mind. They turn to Siri in emergencies or when they want guidance on living a healthier life. Does improving Siri in these areas pique your interest?
Come work as part of the Siri Domains team and make a difference.
We are looking for people passionate about the power of data and have the skills to transform data to intelligent sources that will take Siri to next level. Someone with a combination of strong programming skills and a true team player who can collaborate with engineers in several technical areas. You will thrive in a fast-paced environment with rapidly changing priorities.”
The challenge as explained by Ephrat Livni on Quartz
The position requires a unique skill set. Basically, the company is looking for a computer scientist who knows algorithms and can write complex code, but also understands human interaction, has compassion, and communicates ably, preferably in more than one language. The role also promises a singular thrill: to “play a part in the next revolution in human-computer interaction.”
The job at Apple has been up since April, so maybe it’s turned out to be a tall order to fill. Still, it shouldn’t be impossible to find people who are interested in making machines more understanding. If it is, we should probably stop asking Siri such serious questions.
Computer scientists developing artificial intelligence have long debated what it means to be human and how to make machines more compassionate. Apart from the technical difficulties, the endeavor raises ethical dilemmas, as noted in the 2012 MIT Press book Robot Ethics: The Ethical and Social Implications of Robotics.
Even if machines could be made to feel for people, it’s not clear what feelings are the right ones to make a great and kind advisor and in what combinations. A sad machine is no good, perhaps, but a real happy machine is problematic, too.
In a chapter on creating compassionate artificial intelligence (pdf), sociologist, bioethicist, and Buddhist monk James Hughes writes:
Programming too high a level of positive emotion in an artificial mind, locking it into a heavenly state of self-gratification, would also deny it the capacity for empathy with other beings’ suffering, and the nagging awareness that there is a better state of mind.
Source: Quartz
Artificial intelligence pioneer says throw it all away and start again

Geoffrey Hinton harbors doubts about AI’s current workhorse. (Johnny Guatto / University of Toronto)
In 1986, Geoffrey Hinton co-authored a paper that, three decades later, is central to the explosion of artificial intelligence.
But Hinton says his breakthrough method should be dispensed with, and a new path to AI found.
… he is now “deeply suspicious” of back-propagation, the workhorse method that underlies most of the advances we are seeing in the AI field today, including the capacity to sort through photos and talk to Siri.
“My view is throw it all away and start again”
Hinton said that, to push materially ahead, entirely new methods will probably have to be invented. “Max Planck said, ‘Science progresses one funeral at a time.’ The future depends on some graduate student who is deeply suspicious of everything I have said.”
Hinton suggested that, to get to where neural networks are able to become intelligent on their own, what is known as “unsupervised learning,” “I suspect that means getting rid of back-propagation.”
“I don’t think it’s how the brain works,” he said. “We clearly don’t need all the labeled data.”
Source: Axios
I prefer to be killed by my own stupidity rather than the codified morals of a software engineer
…or the learned morals of an evolving algorithm. SAS CTO Oliver Schabenberger

With the advent of deep learning, machines are beginning to solve problems in a novel way: by writing the algorithms themselves.
The software developer who codifies a solution through programming logic is replaced by a data scientist who defines and trains a deep neural network.
The expert who studied and learned a domain is replaced by a reinforcement learning algorithm that discovers the rules of play from historical data.
We are learning incredible lessons in this process.
But does the rise of such highly sophisticated deep learning mean that machines will soon surpass their makers? They are surpassing us in reliability, accuracy and throughput. But they are not surpassing us in thinking or learning. Not with today’s technology.
The artificial intelligence systems of today learn from data – they learn only from data. These systems cannot grow beyond the limits of the data by creating, innovating or reasoning.
Even a reinforcement learning system that discovers rules of play from past data cannot develop completely new rules or new games. It can apply the rules in a novel and more efficient way, but it does not invent a new game. The machine that learned to play Go better than any human being does not know how to play Poker.
Where to from here?
True intelligence requires creativity, innovation, intuition, independent problem solving, self-awareness and sentience. The systems built based on deep learning do not – and cannot – have these characteristics. These are trained by top-down supervised methods.
We first tell the machine the ground truth, so that it can discover its regularities. They do not grow beyond that.
Source: InformationWeek
Can machines learn to be moral? #AI
 AI works, in part, because complex algorithms adeptly identify, remember, and relate data … Moreover, some machines can do what had been the exclusive domain of humans and other intelligent life: Learn on their own.
AI works, in part, because complex algorithms adeptly identify, remember, and relate data … Moreover, some machines can do what had been the exclusive domain of humans and other intelligent life: Learn on their own.
As a researcher schooled in scientific method and an ethicist immersed in moral decision-making, I know it’s challenging for humans to navigate concurrently the two disparate arenas.
It’s even harder to envision how computer algorithms can enable machines to act morally.
Moral choice, however, doesn’t ask whether an action will produce an effective outcome; it asks if it is a good decision. In other words, regardless of efficacy, is it the right thing to do?
Such analysis does not reflect an objective, data-driven decision but a subjective, judgment-based one.
Individuals often make moral decisions on the basis of principles like decency, fairness, honesty, and respect. To some extent, people learn those principles through formal study and reflection; however, the primary teacher is life experience, which includes personal practice and observation of others.
Placing manipulative ads before a marginally-qualified and emotionally vulnerable target market may be very effective for the mortgage company, but many people would challenge the promotion’s ethicality.
Humans can make that moral judgment, but how does a data-driven computer draw the same conclusion? Therein lies what should be a chief concern about AI.
Can computers be manufactured with a sense of decency?
Can coding incorporate fairness? Can algorithms learn respect?
It seems incredible for machines to emulate subjective, moral judgment, but if that potential exists, at least four critical issues must be resolved:
- Whose moral standards should be used?
- Can machines converse about moral issues?
- Can algorithms take context into account?
- Who should be accountable?
Source: Business Insider David Hagenbuch
Why The Sensitive Intersection of Race, Hate Speech And Algorithms Is Heating Up #AI

SAN JOSE, CA – APRIL 18: Facebook CEO Mark Zuckerberg delivers the keynote address at Facebook’s F8 Developer Conference on April 18, 2017 at McEnery Convention Center in San Jose, California. (Photo by Justin Sullivan/Getty Images)
… recent story in The Washington Post reported that “minority” groups feel unfairly censored by social media behemoth Facebook, for example, when using the platform for discussions about racial bias. At the same time, groups and individuals on the other end of the race spectrum are quickly being banned and ousted in a flash from various social media networks.
Most all of such activity begins with an algorithm, a set of computer code that, for all intents and purposes for this piece, is created to raise a red flag when certain speech is used on a site.
But from engineer mindset to tech limitation, just how much faith should we be placing in algorithms when it comes to the very sensitive area of digital speech and race, and what does the future hold?
Indeed, while Facebook head Mark Zuckerberg reportedly eyes political ambitions within an increasingly brown America in which his own company consistently has issues creating racial balance, there are questions around policy and development of such algorithms. In fact, Malkia Cyril executive director for the Center for Media Justice told the Post that she believes that Facebook has a double standard when it comes to deleting posts.
Cyril explains [her meeting with Facebook] “The meeting was a good first step, but very little was done in the direct aftermath. Even then, Facebook executives, largely white, spent a lot of time explaining why they could not do more instead of working with us to improve the user experience for everyone.”
What’s actually in the hearts and minds of those in charge of the software development? How many more who are coding have various thoughts – or more extreme – as those recently expressed in what is now known as the Google Anti-Diversity memo?
Not just Facebook, but any and all tech platforms where race discussion occurs are seemingly at a crossroads and under various scrutiny in terms of management, standards and policy about this sensitive area. The main question is how much of this imbalance is deliberate and how much is just a result of how algorithms naturally work?
Nelson [National Chairperson National Society of Black Engineers] notes that the first source of error, however, is how a particular team defines the term hate speech. “That opinion may differ between people so any algorithm would include error at the individual level,” he concludes.
“I believe there are good people at Facebook who want to see justice done,” says Cyril. “There are steps being taken at the company to improve the experience of users and address the rising tide of hate that thwarts democracy, on social media and in real life.
That said, racism is not race neutral, and accountability for racism will never come from an algorithm alone.”
Source: Forbes
Machines Learn a Biased View of Women

Two prominent research-image collections—including one supported by Microsoft and Facebook—display a predictable gender bias in their depiction of activities such as cooking and sports. Images of shopping and washing are linked to women, for example, while coaching and shooting are tied to men.
Machine-learning software trained on the datasets didn’t just mirror those biases, it amplified them. If a photo set generally associated women with cooking, software trained by studying those photos and their labels created an even stronger association.
Mark Yatskar, a researcher at the Allen Institute for Artificial Intelligence, says that this phenomenon could also amplify other biases in data, for example related to race. “This could work to not only reinforce existing social biases but actually make them worse,” says Yatskar, who worked with Ordóñez and others on the project while at the University of Washington.
“A system that takes action that can be clearly attributed to gender bias cannot effectively function with people,” he says.
When image-recognition software is “trained” by examining these datasets, the bias is amplified. A system trained on the COCO dataset associated men with keyboards and computer mice even more strongly than the dataset itself.
The researchers devised a way to neutralize this amplification phenomenon—effectively forcing learning software to reflect its training data. But it requires a researcher to be looking for bias in the first place, and to specify what he or she wants to correct. And the corrected software still reflects the gender biases baked into the original data.
One point of agreement in the field is that using machine learning to solve problems is more complicated than many people previously thought.
“Work like this is correcting the illusion that algorithms can be blindly applied to solve problems,” says Suresh Venkatasubramanian, a professor at the University of Utah.
Source: Wired